
The Reliable Computing Platform dispatches the control-law application tasks and executes them on redundant processors. The intended applications are safety-critical with reliability requirements on the order of 1 - 10^{-9}. The reliable computing platform performs the necessary fault-tolerant functions and provides an interface to the network of sensors and actuators.
The RCP consists of both hardware and software components. A real-time operating system provides the applications software developer with a reliable mechanism for dispatching periodic tasks on a fault-tolerant computing base that appears to him as a single ultra-reliable processor. Traditionally, an operating system has been implemented as an executive (or main program) that invokes subroutines implementing the application tasks. Communication between the tasks has been accomplished by use of shared memory. This strategy is effective for systems with nominal reliability requirements where a simplex processor can be used. For ultra-reliable systems, the additional responsibility of providing fault tolerance makes this approach untenable.
For these reasons, the operating system and replicated computer architecture must be designed together so they mutually support the goals of the RCP. A multi-level hierarchical specification of the RCP is shown below.
The top level of the hierarchy describes the operating system as a function that sequentially invokes application tasks. This view of the operating system will be referred to as the uniprocessor specification (US), which is formalized as a state transition system and forms the basis of the specification for the RCP. Fault tolerance is achieved by voting results computed by the replicated processors operating on the same inputs. Interactive consistency checks on sensor inputs and voting of actuator outputs require synchronization of the replicated processors.
The second level in the hierarchy (RS) describes the operating system as a synchronous system where each replicated processor executes the same application tasks. The existence of a global time base, an interactive consistency mechanism and a reliable voting mechanism are assumed at this level.
Level 3 of the hierarchy breaks a frame into four sequential phases. This allows a more explicit modeling of interprocessor communication and the time phasing of computation, communication, and voting.
At the fourth level, the assumptions of the synchronous model must be discharged. Rushby and von Henke report on the formal verification of Lamport and Melliar-Smith's interactive-convergence clock synchronization algorithm. This algorithm can serve as a foundation for the implementation of the replicated system by bounding the amount of asynchrony in the system so that it can duplicate the functionality of the DS model. Dedicated hardware implementations of the clock synchronization function are a long-term goal.
The LE model was completed in June 1994. This model describes the actions on each local processor delineating how each processor schedules tasks, votes results and rewrites its own local memory with voted values. Of primary importance in this specification is the use of a memory management unit by the local executive in order to prevent the overwriting of incorrect memory locations while recovering from the effects of a transient fault. There will probably be another level of specification introduced before the final implementation in hardware and software is reached. The research activity will culminate in a detailed design and prototype implementation. The figure below depicts the generic hardware architecture assumed for implementing the replicated system.
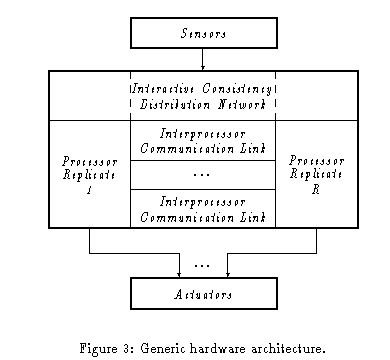
This hardware architecture is a classic N-modular redundant (NMR) system with a small number N of processors. Single-source sensor inputs are distributed by special purpose hardware executing a Byzantine agreement algorithm. Replicated actuator outputs are all delivered in parallel to the actuators, where force-sum voting occurs. Interprocessor communication links allow replicated processors to exchange and vote on the results of task computations. As previously suggested, clock synchronization hardware may be added to the architecture as well.
NASA LaRC formal methods team has orchestrated the effort to apply formal methods to the RCP. The design problem has been decomposed into several separate activities as illustrated below.
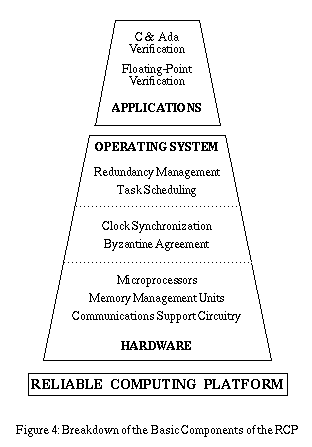
The NASA Langley team concentrated on the system architecture for the RCP. The top two levels of the RCP were originally formally specified in standard mathematical notation and connected via mathematical (i.e. level 2 formal methods) proof. Under the assumption that a majority of processors are working in each frame, the proofs establish that the replicated system computes the same results as a single processor system not subject to failures. Sufficient conditions were developed that guarantee that the replicated system recovers from transient faults within a bounded amount of time. SRI subsequently generalized the models and constructed a mechanical proof in Ehdm.
Next, the NASA Langley team developed the third and fourth level models. The top two levels and the two new models were then specified in Ehdm and all of the proofs were done mechanically using the Ehdm 5.2 prover. The Phase 2 paper was published on completion of these proofs.
The Langley team then began work on the LE level. This model was in turn broken up into two levels. We completed all the necessary proofs of both of these levels using Ehdm 6.1, and published a Phase 3 report.